
16 - 18 June 2026
The next Industrial Data Science Workshop will take place from 16 - 18 June 2026
Registration is expected to open will open early in 2026
Now an IChemE approved course
Course participants will be introduced to process data challenges and how to solve them with data science. The syllabus is geared towards general Machine Learning concepts for regression models (supervised learning) and anomaly detection (unsupervised learning).
The focus, however, will be around the application of industrial data science techniques and GenAI to continuous and batch process data, so a subject domain expert (e.g., process engineers) can perform the following data-driven analysis independently:
- Extract and transform process data
- Quantify variability and identify relevant process changes
- Quickly find potential causes to improve processes
At the end of each day, there will be sessions to perform individual hands-on exercises allowing participants to use their own datasets in their own laptops (in Excel, CSVs, or from Aspentech IP.21 and Osisoft PI systems).
Basic knowledge of statistics (e.g., six sigma training) can be helpful to fully understand the concepts of this course. A programming background (Python, MATLAB…), is not required.
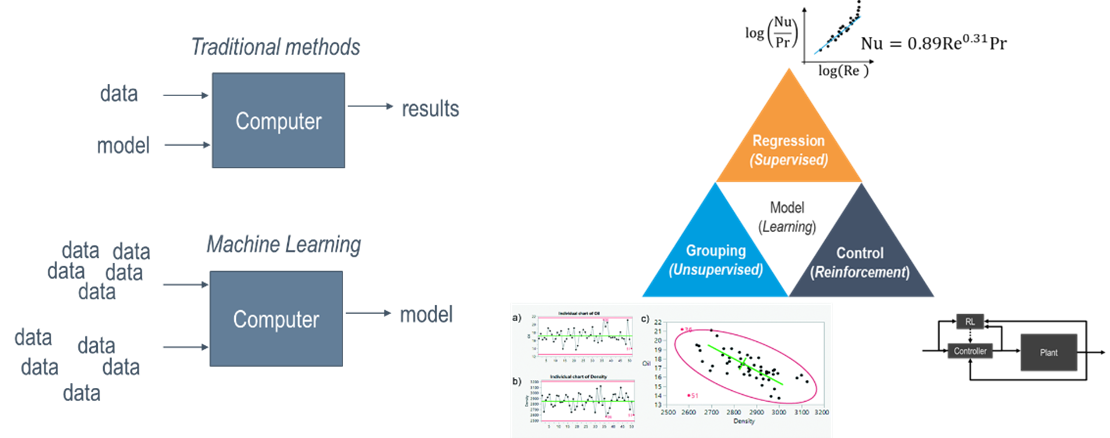
Day 1 – Industrial data science and GenAI
- Introduction to Industrial data science and GenAI
- Distillation tower (full example)
- Industrial databases (tags, historians, and automation pyramid)
- Contextual data (asset hierarchies, batch events)
- Quality and tabular data (LIMS, ERP)
- Data democratization and software alternatives in industry
- Hands-on session (connect to databases with Excel, ODBC, and RestAPIs).
Day 2 – Monitoring assets
- Batch dryer example
- Defining KPIs for continuous and batch processes (feature engineering)
- Tracking variability (visual analytics, statistical process control, robust statistics)
- Batch data alignment (e.g., time warping)
- Machine learning for anomaly detection (KNN, PCA, Autoencoders)
- Identifying plant changes in the Tennessee Eastman Process
- Hands-on session (Bring your own data!)
Day 3 – Troubleshooting processes
- Problem definition
- Screening process variables (bootstrap forest, decision trees, and boosted trees)
- Improving processes (sensitivity analysis, explainable AI with SHAP)
- Modelling processes (missing data, Lasso regression, and neural networks)
- Industrial applications (inferential sensors and digital twins)
- Hands-on session (Bring your own data!)
The course will be delivered by:
Dr. Francisco Navarro (Data Science Director at IFF and Visiting Researcher at Imperial College London) [in]
Senior Data Science Training Lead, Imperial College London Visiting Researcher and chemical engineer working at IFF, a global leader and manufacturer in flavors, fragrances, food ingredients, and health and biosciences.
Francisco Navarro is leading the data democratization of AI/ML in manufacturing, where production engineers use industrial data science and GenAI to monitor, troubleshoot and optimize their processes. Instead of solutions that require support and only number-up, we scale-up the impact via data-driven literacy and self-service analytics. His industrial and research experience in Solvay, P&G, and Bayer uniquely combined data-driven methods with manufacturing systems, advances process control and process systems engineering.
He holds a Ph.D. in modelling and simulation where he designed (and patented) multiphase-flow sonoreactors. He also visited Prof. Jensen’s lab at MIT (USA) during his doctoral studies. In 2012, he co-created cacheme.org, an open-source ChemE organization based at the University of Alicante (Spain).
Prof. Mattia Vallerio (Tenure Track Assistant Professor and Advanced Process Control Specialist) [in]
Prof. Mattia Vallerio is a Tenure Track Assistant Professor at Politecnico di Milano, where he leads the Sustainable Process Systems Engineering (SuPSE) Lab. His research focuses on advancing Process Systems Engineering (PSE) with a strong emphasis on sustainable (bio)chemical processes, artificial intelligence, and advanced process control. His work integrates machine learning, generative AI, and process intensification to develop innovative solutions for process modeling, simulation, optimization, and control.
With 10+ years of experience, he has contributed to the digital transformation and performance optimization of chemical production sites across Europe, working with SABIC, DOW, BASF, Solvay & Syensqo. His expertise spans cross-functional project and team management, industrial AI applications, and operational excellence best practices.
Before joining academia, he served as Manufacturing Excellence Site Manager at Syensqo’s Spinetta Marengo site, leading digital transformation initiatives, advanced process control implementations, and industrial data analytics.
Prof. Vallerio holds an M.Sc. in Chemical Engineering from Politecnico di Milano and a Ph.D. in Engineering Science from KU Leuven. He is an active member of the Computer Aided Process Engineering (CAPE) Working Party and serves on the Council of the Italian Association of Chemical Engineering (AIDIC).
Dr. Carlos Perez (Industrial Data Scientist at Syensqo (ex Solvay) and Optimization Specialist) [in]
Carlos Perez Galvan is an Industrial Data Scientist at Syensqo in Brussels, Belgium. Currently, he is the technical leader of an Advanced Analytics corporate team that collaborates with all of Syensqo's businesses.
In cooperation with the Advanced Process Control team, he focuses on leveraging data analytics, process control and process systems engineering methods to optimize plant performance.
During his 7+ years career in P&G (modelling and simulation) and Syensqo he has had the opportunity to develop practical expertise in the fields of modelling, simulation, optimization and machine learning.
He holds a Ph.D. in Chemical Engineering from University College London. He graduated from Universidad Autonoma de Coahuila in Mexico as a Chemical Engineer in 2012.
The instructors combine more than 20+ years of industrial data science experience covering machine learning, first-principle modelling and simulation, optimization, process control, and chemical engineering applied to chemical and process industries.
Their research is co-authored with Reinforcement Learning experts from Imperial College London and Manchester University:
- Industrial data science – a review of machine learning applications for chemical and processes industries [React. Chem. Eng., 2022, 7, 1471]
- Industrial Data Science for Batch Manufacturing Processes (arXiv:2209.09660v1 [cs.LG] 20 Sep 2022
Registration Fee:
- To be confirmed
Cancellations
Full refunds, less 20% administration fee, will be given for cancellations that are received in writing on or before 15 May 2026. After this date, until 29 May 2026, participants who cancel will receive refunds of 50% of the registration fee paid. No refunds will be provided for cancellations received after 29 May 2026.
Substitutions may be made at any time, whilst a valid place is held. The organizer cannot accept liability for costs incurred in the event of a course having to be cancelled as a result of circumstances beyond its reasonable control.
Venue: The Sargent Centre for Process Systems Engineering
Imperial College London
Roderic Hill Building
South Kensington Campus
London SW7 2BB
For the campus website, use this link.
Closest Underground Stations are South Kensington or Gloucester Road.
Accommodation can be booked via the below websites.
Please note that Imperial College has no affiliations with these websites and other websites are available.

![]()